Optical Character Recognition (OCR) may just be better than sliced bread for anyone who must convert pages of text to editable text. maybe you have pages of text that you scan onto your PC and now it must be converted into a form that is editable. Maybe there isn’t enough time to type, or it is just too much to type. Well, Optical Character Recognition can help with just that. You can scan the pages onto the computer and open them with Adobe Acrobat and attempt to use the OCR function to recognize the text and give you an editable version. Just as you are about to do the victory dance you get the error Acrobat could not perform recognition (OCR) on this page because This page contains renderable text.
Adobe OCR not recognizing text
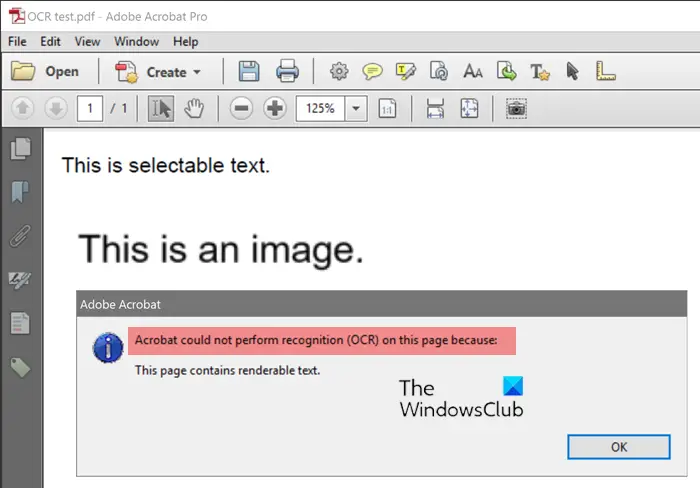
Acrobat Professional has OCR capabilities that allow you to save scanned documents in Rich text format or as Microsoft Word Documents, both Doc and Docx. There may be an instance when you open the document in Adobe Acrobat professional and you can see the text however, Acrobat is giving an error. Acrobat is not able to use OCR on the text, there may be a few reasons why this is happening.
- Renderable/editable text
- Distorted or blurred source
- Low-quality original
- Graphics and forms
Acrobat could not perform recognition (OCR) on this page because This page contains renderable text
1] Renderable/editable text
Renderable text is the editable text that exists within the file that you want to do OCR on. Acrobat cannot perform OCR on a document that contains renderable text. This is the least obvious reason for the OCR scan error because we always assume that readable text should also be scannable by OCR.
Solution:
There are two ways to deal with the error if this is the problem.
- Try to obtain a copy of the document that does not have renderable text.
- Convert the PDF to TIFF then back to PDF and retry the OCR.
To convert the PDF to TIFF open it in Acrobat and go to File then Save as. When the Save as dialogue box appears choose TIFF (*.tif, *.tiff) from the Save As Type. Specify a location where you want the file to be saved then click save. Acrobat saves each page of the PDF document as a separate, sequentially numbered TIFF file. You then open each of the TIFF files and use Acrobat to run OCR on them.
If you want to combine the documents into one, do the following:
- Open Acrobat, choose File then Create PDF then From Multiple Files.
- Select Browse to select and add each PDF file. Rearrange the files in the way that you want them to appear in the new PDF.
- Select OK.
2] Distorted or blurred source
Blurred document
Another reason for Acrobat to be unable to perform OCR on the document is if it is of low resolution. Low-resolution documents may become blurry, and Acrobat will not be able to perform OCR on them.
Solution:
Get a high-resolution source of the document. If you are scanning from a paper document, adjust the resolution of the scanner so that it will take a higher-definition scan.
Distorted document
Acrobat may not be able to perform OCR on a document that is not properly aligned. The document may have not been scanned straight so Acrobat is not able to perform OCR on it.
Solution:
Ensure that the paper that you are scanning from is straight before you begin the scan. You can also open the distorted document in Photoshop and straighten it. Here is a post that will show you how to use the straighten tool in photoshop. This tool can help you straighten the scanned document before you perform OCR in Acrobat.
3] Low-quality original
When the source material is of low quality, for example, fax, Acrobat may not be able to perform OCR on it properly. You will then have to seek to get better quality or risk having to fix the output.
Solution:
Get a better quality source to perform OCR on. If the low-quality document is all that you have, you may have to run the OCR and hope that at least some are recognized then type in the missing parts.
4] Graphics and forms
Documents that have graphics and forms mixed in will not be processed by OCR in Acrobat. Documents to be used for OCR by Acrobat should have no graphics or forms mixed in or it may give an error, or the output may be incorrect.
Solution:
Find a plain text version of the document to perform OCR on. You may also have to perform OCR on the document with the graphics and forms, if it works then you may have to do corrections to the output.
What is OCR in Adobe Acrobat?
OCR is the process by which Acrobat examines a pixel-based text or picture. Each character is recognized and turned into text. Acrobat compares the image shape and the line thickness to the fonts already installed on your PC during the OCR process. Below are the reasons for the OCR scan error.
What file format is not the best for OCR?
The JPEG file format is not the best for saving for OCR as JPEG tends to lose its quality each time it is saved. Even if you convert the JPEG to a PDF, it may still be of low quality. It is best to save the documents as PDF or TIFF if you intend to do OCR on them.